
Station Overseer
Optimizing 2D map generation in C#
Hello everyone.
Recently the map generation capabilities in Station Overseer were optimized, enabling map sizes up to 3000x3000 (almost 1 million tiles). Previously, a 300x300 map would take 22 seconds to generate, whilst a 500x500 now only takes 12. Overall this improved map generation speed by up to 86%!
This is going to be an in-depth post explaining what was done to achieve this. More specifically, about optimizing the tile-based data structures used in generating the map. Although the game uses the Unity engine, the optimizations were primarily related to the C# code, and not of any engine features themselves.
Firstly, this post will introduce you to the terminology and how the data structures are used in the game, whereafter optimizations of their code and data structures are shown. The post is quite long, so feel free to skim the headers provided to find a section that interests you, otherwise the whole journey is there, all in chronological order!
Introduction
What do tiles, regions and rooms do?
Station Overseer is a top-down game, utilizing a 2D grid map.

A picture showing part of a standard 300x300 map.
There are two different systems utilized in generating and processing the map.
- The Map Generator uses a noise map to generate asteroids semi-randomly.
- The Region Manager sets up each individual Tile, groups them into Regions, which are finally grouped into Rooms.
The most expensive part of this process the by far the latter, which is what this post will showcase the optimization of. In a complex game like this, the Region Manager must keep track of data structures to be used for various processes in the game. Some of these include collision, atmospherics, possibly lighting and finding nearby objects/items.
Tiles
Tiles keep track of walls, pipes and parts of a station that are open to space.
- Walls, doors, objects and outer space affects pathfinding.
- Oxygen tanks are connected by pipes to vents.
- Gases dissipate if a tile is exposed to the vacuum of space.
Regions
Regions keep track of objects and items inside them, aiding nearest-search algorithms.
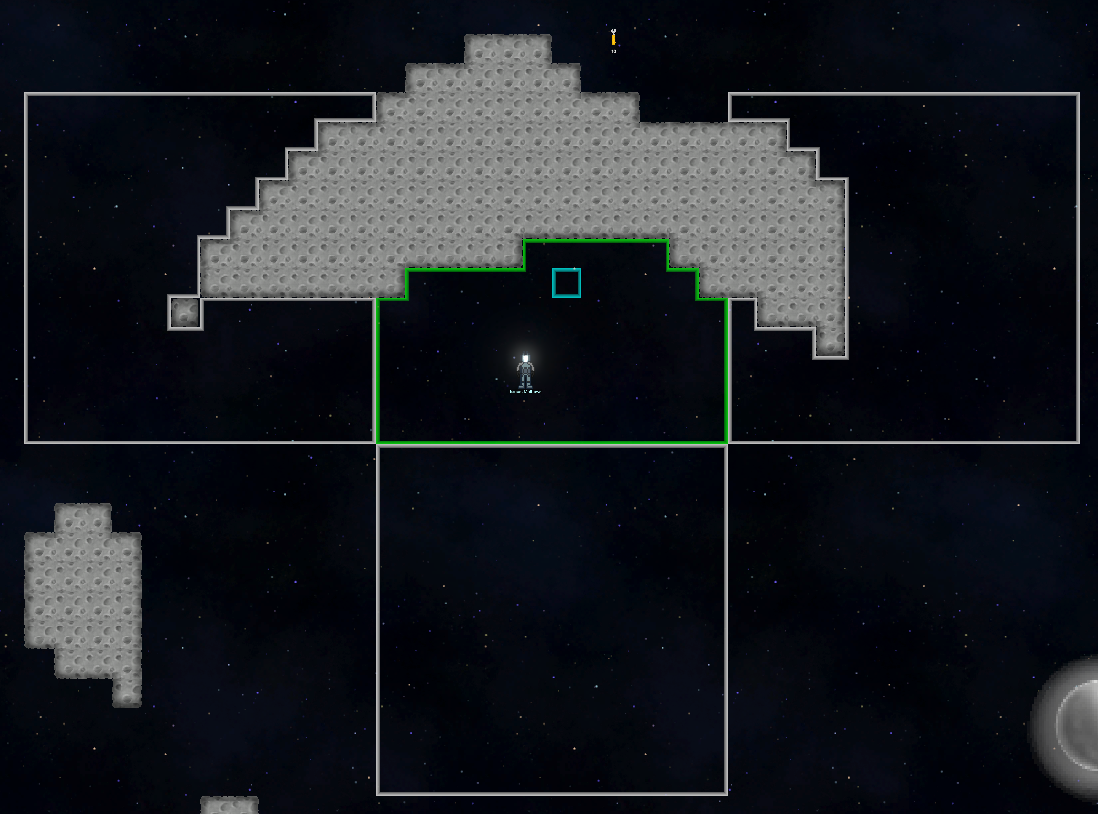
A green Region below an asteroid, showing its 3 neighbouring Regions.
This person looking for his tools will try to look below or to the side before checking the other side of an asteroid. Looking for items becomes as simple as floodfilling through the regions, since their connections approximate the distance around walls quite well.
Rooms
Rooms group this up further and is great for categorizing and keeping track of enclosed spaces.

A Room colored in beige, along with some of the Regions it consists of, along with the connected doors in various colors.
This ensures doors and atmospherics play together nicely. Gases can flow between Rooms, and any Room exposed to space can suck out the gases.
Optimizing
How do we make this as fast as possible?
For optimizing, Unity provides developers with a profiler to show execution times of their code and different game processes. This is very useful for comparisons, and to measure the parts that need optimization. This section will include various screenshots of these profiler results as the process was optimized.
As explained in the previous section, the RegionManager keeps track of, and generates these data structures. This generation is performed in a 4-step process.
- Creating Tiles
- Creating Regions
- Assigning Region neighbours
- Creating Rooms
Conveniently, each step is cheaper performance-wise than the one before it, with Tile and Region creation being the most expensive. Below is a picture of some of the very first profiler results on what was most likely a 200x200 map.

If you're not used to this, it may seem a little overwhelming. To break it down shortly: the function names are displayed on the left, with their associated costs on the right. There are two important numbers here. "Time ms" is the most important, showing the functions total execution time in milliseconds. "GC Alloc" relates to memory usage, and will often come back to bite you in terms of CPU usage too. I won't go into depth on GC here, but we don't have to worry about it too much, as long as it doesn't run rampant.
Switching from a Dictionary to a 2D Array
The first step to optimizing this was very easy. Originally the game kept a dictionary of tiles that existed. A dictionary is a collection of <key, value> pairs. Tiles were categorized by their position, so they were <Vector3Int, Tile> pairs, utilizing Unity's Vector3Int struct.
Dictionary<Vector3Int, Tile> tiles = new Dictionary<Vector3Int, Tile>(); Vector3Int pos = new Vector3Int(0, 0, 0); tiles[pos]; // Accessing a tile
The dictionary was used because tiles didn't include walls back then, which meant not every position inside the map bounds was guaranteed to hold a tile. This quickly turned out to be a pointless distinction, as checking for valid tiles constantly came with a huge overhead. This was changed long ago, so that every position inside map bounds is a tile, including walls. However, the dictionary stayed around until now.
Dictionaries are great, they can be resized like a list, but can hold a whole vector as a key. But they also come with quite a bit of overhead: it takes up a lot of memory, and accessing it is slow.
But now that every position is always a tile, we don't need to resize it as the map changes, we already know the size should be mapWidth * mapHeight. In fact, we don't even need a vector. The natural solution was switching to a 2D array.
Tile[,] tiles = new Tile[mapWidth, mapHeight]; tiles[0, 0]; // Accessing a tile
The only problem is that you cannot use negative numbers when accessing arrays, but our 200x200 map went from -100 to 100. That's not a deal-breaker though, the simple solution would just be to use our position + 100 every time we access it, so we go from 0 to 200.
To simplify this process, we would just use a custom class to do this for us.
class Coordinate2DArray<T>
{
private T[,] array;
public Coordinate2DArray(int width, int height)
{
array = new T[width, height];
}
public T this[int x, int y]
{
get
{
return array[x + mapWidth / 2, y + mapHeight / 2];
}
set
{
array[x + mapWidth / 2, y + mapHeight / 2] = value;
}
}
}
Coordinate2DArray<Tile> tiles = new Coordinate2DArray<Tile>(mapWidth, mapHeight);
tiles[0, 0]; // Accessing a tile
With generics we can even use this for any data type we want, not just Tiles!
And the result:

Much better, not only did it lower the memory usage, it also cut the execution time in half! But I was about to go much lower than this...
Floodfilling at scale
Time to bump it up to 500x500!

Oh. Well atleast it doesn't give a runtime error anymore, it's actually possible. Still it almost takes half a minute. That's not great.
So what's wrong? Floodfilling of course! Do you want to loop through 15 million tiles? Neither does Unity.

When you end up with 15 million calls, optimizing may only do so much. Clearly it's better to find a way to prevent this. So what's happening?
Whenever we create a tile that has a pipe in it, we need to check what it's connected to.
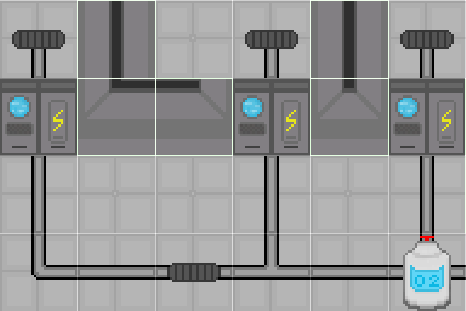
This is done with a floodfill: check every adjacent tile, if it's a pipe we check that one's adjacent tiles too, and repeat until there are no more pipes left (It's a little more complicated than that). We can use this to check if vents and oxygen tanks are connected. Great, simple, no problem.
The problem arises when we want to ensure we're not visiting the same tiles on repeat. Every time we move to an adjacent pipe, we need to know we've already checked the pipe behind it, otherwise it'll keep looping back and forth infinitely.
To do this, I have an additional field on every tile that keeps track of whether it's been visited or not. The problem with this approach is, that we need to reset the state of every tile when we finish the floodfill. The alternative would be creating a list of positions we've visited, that would just be thrown (garbage collected) away when we're done. No need to loop through every tile again. Of course the tradeoff is garbage collection, keeping a list of all the visited tiles costs memory, which as mentioned before will come back to bite you and cost additional CPU.
An example of this can be seen underneath, where fields are actually more viable in very big floodfills. The top being fields reset through ResetTilesVisited, with the bottom using hash sets instead.
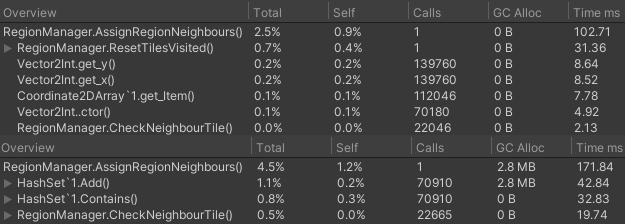
In the above example, looping through and resetting the field of every tile is actually faster than storing all the visited ones in a hash set. In this case, most of them are being visited anyways, so storing them all in a hash set gets very expensive. Performance-wise, this is due to keys being a little slow. This was even after optimizing keys in the next section. But not only is this slower, it also requires a lot of memory! 2.8 MB of garbage is generated in this example, while fields are free.
At a small scale, where we may only visit 10 tiles, there's no point in looping through all 250 thousand tiles to reset them. Making a small list is actually viable at this scale: we don't visit many tiles, so the list won't take much memory. At large scale the former option is preferable however, as creating multiple lists of close to 250 thousand visited positions isn't a great idea.
Unfortunately there is an additional CPU cost to this. Instead of simply checking the value of a tile's field, we need to run through the list and check if it already contains the tile we're trying to visit. To complicate this further, different collection types alter these costs in different ways. So let's test them all:
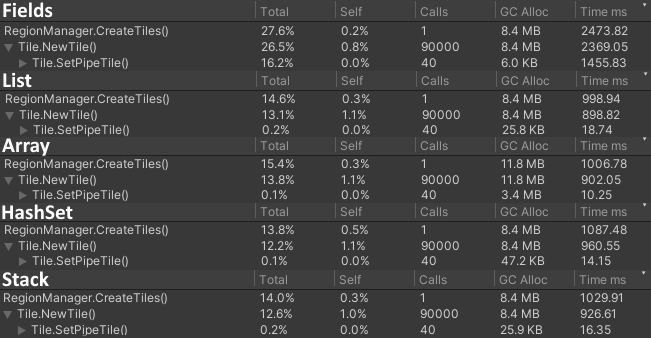
Wow, that's a lot of numbers. In summary: fields are clearly the slowest, taking over a second compared to the rest. The rest are pretty even around 10 ms. That may not seem like a lot, but with more pipes and bigger maps it quickly becomes way more.
Arrays stand out as being inefficient memory-wise at 3 MB compared to the rest at 20-40 kB. This is because we cannot know how many tiles we're gonna visit in advance, and therefore don't know how big it should be. A stack makes little sense; it's essentially a list suited for a different purpose, even if it seems a little faster in this test.
Hash sets are like lists, but without an order. What's so great about that? Well instead of everything being ordered by a number, it uses unique keys for each value. This means checking if it contains a previously visited position, we don't have to loop through the whole list, checking the elements one by one. Instead we just check if it contains the proper key. This is O(1) instead of O(n). While it does produce more overhead, and looks more expensive in the above screenshot, it scales better. That is very important if our pipe-network becomes much larger, and you don't want your game to crash (I learnt the hard way).
But keys and values, that's kind of like our previous dictionary? Except we're not storing both keys and values, just the values. Previously we used tiles as values, but we don't need to use them for anything, just to know if their position has been visited. So we just store the positions as values in a hash set. This allows for other performance benefits.
Improving upon Unity's vectors in HashSets and Dictionaries
Now that we're storing positions in hash sets, C# will be generating unique keys for us to make them work within this data structure. Why do we need to worry about this? Performance of course! We may not be looping through the whole dataset, but the overhead of adding and checking if they contain positions is all dependent on how fast these keys can be generated.
As was mentioned in the section where I switched from storing tiles in a dictionary, I have been using Vector3Int so far to store positions. Clearly this wasn't gonna cut it. First of all, the game is 2D: we only need an X- and Y-coordinate, with the 3rd Z-coordinate just taking up extra memory. Not only that, but generating a key is done depending on these values, meaning it would be faster to just use 2 coordinates.
The below example is from optimizing the tiles stored in regions. At this time a dictionary was still used for this, although it was later switched out. Still, the performance benefits hash sets too.
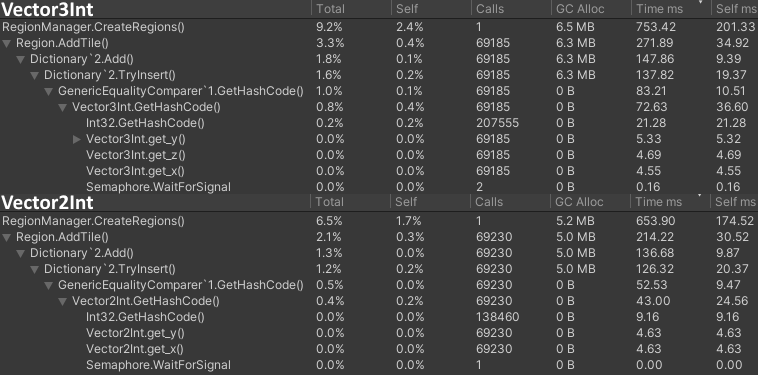
Not a large difference, but as expected it definitely looks a little better: less GC Alloc and slightly improved execution time. The GetHashCode function was almost halved, but is definitely still the most expensive calculation here. It was time to dive into Unity's vector structs. For a hash set or dictionary to generate the keys of a struct, it uses the GetHashCode function.
Improving Unity's vectors
In C#, structs have a default GetHashCode implementation, but making your own will always be better. This can be done by inheriting from IEquatable, and luckily Unity has already done that.
struct Vector2Int : IEquatable<Vector2Int>
{
public override int GetHashCode()
{
return x.GetHashCode() ^ (y.GetHashCode() << 2);
}
}
It includes some fancy bit manipulation to generate unique keys for all vectors. And while it could be worse, it unfortunately isn't necessarily the fastest due to the cost of the two additional method calls. Even if that was inlined, the calculation isn't necessarily cheap on its own. It is also important to note that Unity is not great at inlining methods, even when it should. This is even true when converting the code to C++.
C# doesn't provide a way to override this method without access to Unity's structs, so we must create our own struct!
struct Int2 : System.IEquatable<Int2>
{
public override int GetHashCode()
{
return x * 49157 + y * 98317;
}
}
I used an Int2 struct with a relatively cheaper method. This should provide it with enough unique keys for our use-case. Bring in the results!
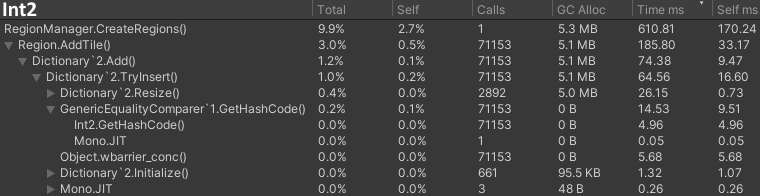
Getting hash codes suddenly went from the previous 83 and 52 milliseconds to just under 15! This all adds up when working on bigger maps, except it didn't change the overall performance that much. Instead most of it was now being spent on type-casting, as can be seen in the below Int2.op_Implicit.

This Int2 struct was great and all, but I was still using Vector2Int everywhere else, resulting in a lot of type-casting where it mattered the most. Casting is generally extremely cheap, but as with anything, it stops being healthy when doing it over 71 thousand times. This meant changing most parts of RegionManager to use Int2 instead, avoiding Vector2Int almost completely. This is most important during the high intensity calculations while generating the map, whereafter it stops mattering.

Finally we actually see the big difference we were trying to get. The execution time necessary to create regions was cut in half. But we can do better than that!
A trick for even faster Dictionaries and HashSets
When using hash sets and dictionaries, there's a small very simple trick that may bring up the performance even more. When initializing one of these collections, we can provide a custom IEqualityComparer class in its constructor to generate keys, instead of using the GetHashCode method in our IEquatable struct or class.
This can just be a class that includes the very same GetHashCode method of our desired struct or class.
class Int2Comparer : IEqualityComparer<Int2>
{
public bool Equals(Int2 e1, Int2 e2)
{
return e1.x == e2.x && e1.y == e2.y;
}
public int GetHashCode(Int2 e)
{
return e.x * 49157 + e.y * 98317;
}
}
So what's the benefit? Well, you can see the difference below. The top being with a custom Int2Comparer, and the bottom just using Int2's GetHashCode function.
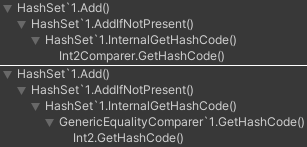
Without an explicit comparer, the collection calls an intermediary GenericEqualityComparer method, that has to then call our GetHashCode. That's an extra step, even if we disregard the extra method call cost overhead due to possible inlining, it still just costs slightly more. Providing our own Int2Comparer skips that extra step, optimizing the code just slightly more.
Another switch from a Dictionary to a List
When storing tiles I initially used dictionaries. Now that there's a guaranteed tile in every position, a 2D array made a lot of sense to switch to. But as can be seen in the previous section, I was still using dictionaries for the regions to keep track of their tiles. Not all regions are of the same size, so a resizable collection makes a lot of sense. But that still doesn't justify a dictionary.
As explained before, a dictionary contains a <key, value> pair. In this instance it had become an <Int2, Tile> pair. But since I already had the 2D array to lookup tiles by their positions, I might as well limit the regions to just store their Int2 positions only.
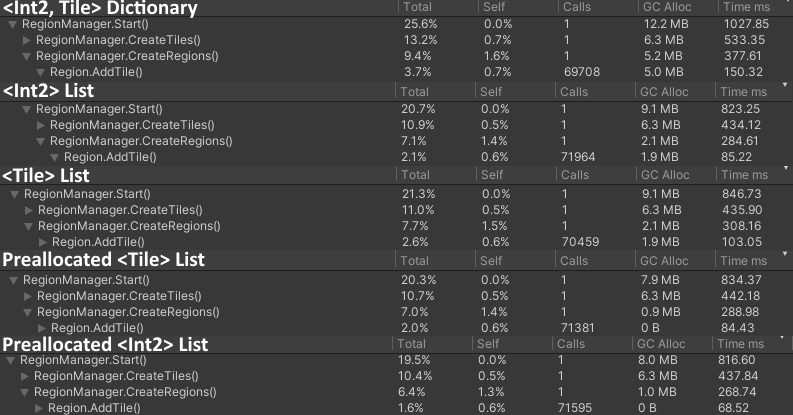
Both forms of lists outperformed the dictionary not just in execution time, but also memory usage. Additionally, Int2 lists outperformed Tile lists everywhere, even with more calls. Not only that, but preallocation helped even more. How does that work if we don't know the size of the region beforehand?
Many regions are often gonna be at or close to their original size. So as an approximation we can simply preallocate them to their max size, whereafter C# automatically downscales for us as needed. This isn't always the most efficient if the variability is too high, but in this case it gives clear performance benefits.
With all these improvements in place, it's just a matter of implementing them. Using hash sets where fields are expensive, and vice versa.
End note
These improvements helped get Station Overseer from a stable 200x200 map to 3000x3000. It doesn't necessarily need that size, but the capability and performance benefits at a whole are very nice. Beyond that, the game struggled to produce even a 300x300 map. These optimizations are also needed for general runtime floodfilling, as well as other algorithms that are being implemented in later updates. For an example of a 3000x3000 map, I will refer to the picture from the update devlog.

Can you spot the station?
There are even more performance benefits that can be achieved, but at that point I'll have to rework how the whole game works and disconnect even further from Unity. That won't be necessary... yet.
This is my first technical write-up like this. Since I had plenty of collected profiling documentation lying around after the update, it's great to be able to collect them in a single post, along with a short explanation of the underlying region system.
I hope the read was interesting, and possibly even helped another developer get some insights into how optimizing such a system works. If anything above did help you, do let me know!
Leave a comment
Log in with itch.io to leave a comment.